TCP flow control and asynchronous writes
Overview
To enable network applications to send and receive data via a TCP connection reliably and efficiently the TCP protocol includes flow control which allows the TCP stack on one side of the connection to tell the TCP stack on other side of the connection to slow down its data transmission, or to stop sending data entirely. The reason that this is required is that the TCP stack in each peer contains buffers for data transmission and data reception and flow control is required to prevent a sender from sending when a receiver’s buffer is full. The flow control is accomplished by adjusting the window size of the sliding window acknowledgment system that is used by TCP.
With asynchronous networking API’s, the receiving application controls the lifetime of the sending application’s send buffers.
TCP flow control
We don’t need to delve too deeply into understanding TCP’s sliding window acknowledgment system here, a simplified view is enough for the purposes of this article. Lets assume we have a sender and a receiver connected by a TCP connection. The sender has a send buffer which it uses to queue data that needs to be sent to the receiver and which also stores data that has been sent but that has not yet been acknowledged by the receiver. The receiver has a receive buffer which is used to store data that has arrived and which may have been acknowledged but which has not yet been processed by the receiving application. The receiving application uses an API to read data from the receiver’s receive buffer. The sending application uses an API to add data to the senders send buffer. The sender and receiver transfer the data reliably and efficiently between themselves.
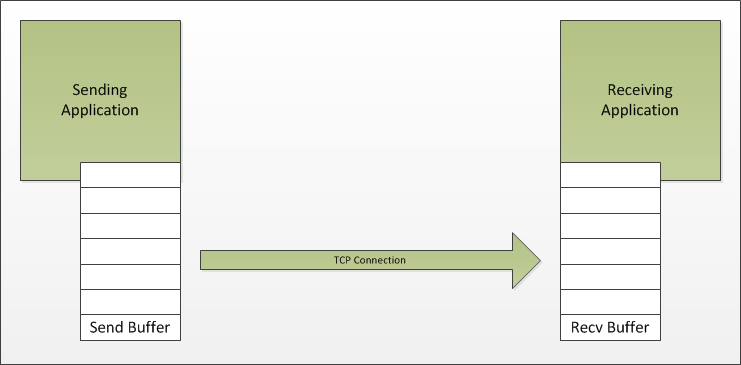
A simple view of TCP's buffering
Why do we need TCP flow control?
Flow control is required because the sender may wish to send data faster than the receiver can process it. This can happen if the receiving application is processing data slower than the sending application is generating it.
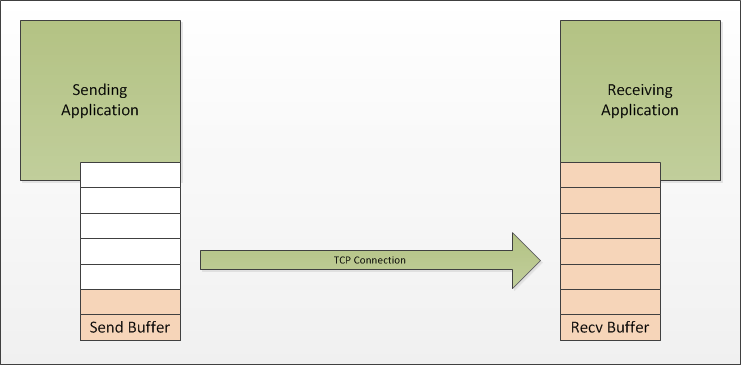
The receiver's buffer can become full
If the sending application is using a blocking API then the thread in the sending application that is writing to the network will stop and wait when the sender’s buffer is full. The receiving application can then ‘catch up’ and the sending application will simply run slower as it is now being throttled to the speed that the receiving application can process the data.
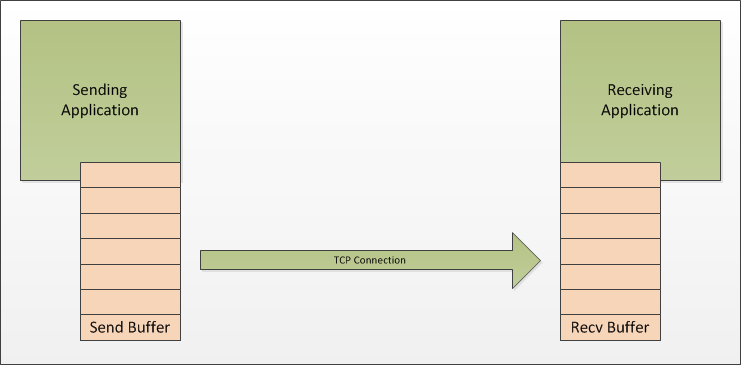
The sender's buffer then becomes full
Asynchronous network APIs
Things are a little more complex with an asynchronous sending API such as the API to the Windows Overlapped I/O system. With an asynchronous sending API the sending application is not blocked when the sender’s send buffer is full. Instead the API queues the data for sending once the sender’s buffer has space, this is, of course, a simplified view of things. The important thing to understand is that the sending application is now no longer throttled to the speed of the receiving application. Nothing in the sender’s asynchronous API will prevent the sending application from generating more data than the receiving application can process and so the sending application itself must take responsibility for not sending more than the receiver can receive.
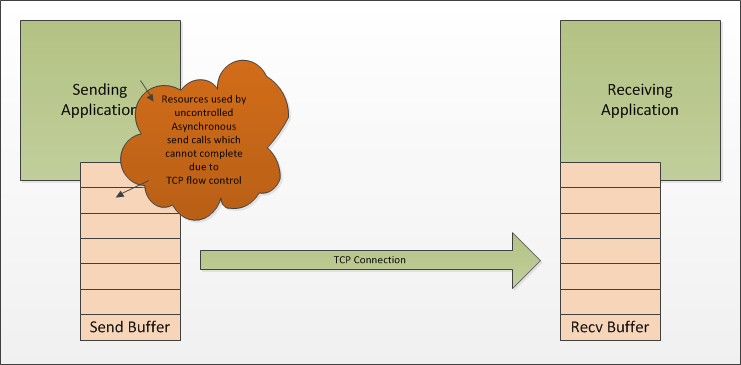
The async memory balloon
If the sending application ignores the fact that the receiving application might not be able to consume data as fast as it can generate it then the sending application will use memory and other resources in an uncontrolled manner. For example, the sending application may be allocating memory to use as buffers for the data that it is sending to the receiver. If the receiving application can consume data faster than the sending application can generate it then the amount of memory used by these buffers in the sending application appears controlled; they are used for as long as necessary to transfer the data from the sender to the receiver. However, if the receiving application cannot consume the data as fast as the sending application can generate it then it quickly becomes apparent that the sending application is, effectively, handing over control of its memory management to the receiving application. The buffers are still only used for as long as is necessary to transfer the data from sender to receiver but that duration is not under the control of the sending application. Of course, this was always the case, but when the receiver can consume faster than the sender can send it’s easy to forget. With asynchronous send API’s, the receiving application controls the lifetime of the sending application’s send buffers.
With asynchronous networking API’s, the receiving application controls the lifetime of the sending application’s send buffers.
Even if the receiving application can be guaranteed to always consume data faster than the sending application can generate it the sending application is still at the mercy of the network. If the network becomes congested, or if the receiving application is on the end of a network link that cannot transfer data as fast as the sending application can generate it then the sending application is back in the same situation as it was with a slow receiving application. The sender’s send buffer will fill up and the asynchronous send API will allow the sending application to continue to queue data to be sent.
In addition to the memory used for the buffers used in asynchronous sends, the Windows Overlapped I/O system also uses some non-paged pool memory for each overlapped operation. This is small, and largely undocumented, but non-paged pool memory is a scarce resource on pre-Vista operating systems and, even on Vista and later, it’s a resource that can be exhausted and when exhausted can place the operating system into a potentially unstable state. See here for more details on non-paged pool.
What about .Net?
With managed code this problem is even worse. With the managed asynchronous APIs your managed send buffers need to be pinned in memory whilst the I/O operation is in progress. The pinning of numerous I/O buffers causes the garbage collector problems; it can’t reorganise the managed heap as much if there are pinned objects. This causes fragmentation in the managed heap and that can lead to the managed memory system failing memory allocation requests due to the inability to allocate memory of the required sizes.
How do we fix this?
There are several ways to avoid handing over control of your resource lifetime. Firstly it may be that your application level protocol can be designed in such a way that it supports its own flow control. This would allow your receiving application to send flow control information to the sending application and would allow the sending application to stop issuing asynchronous sends when the receiving application asks it to. Note that this isn’t in any way specific to asynchronous network operations and that a robust application level protocol should include flow control where possible as it makes it easier to design the client and server.
Application level flow control isn’t always possible. In these cases you need to actively manage the number of outstanding asynchronous send operations on each TCP connection. The Windows Overlapped I/O system provides you with completion notifications when your I/O operations have been completed. This is the point at which you can release or reuse the data buffers that were used for the I/O operation. Note that the completion notification for a network send operation does not mean anything more than that the TCP stack on the sender has taken responsibility for the data; in our diagrams above, you’d likely get completion notifications when the data has been copied into the sender’s send buffer.
When the sender’s send buffer is full your send completions will take longer to occur, if you increment a counter when you issue an asynchronous send operation and you decrement the counter when the operation completes you can track how many operations are pending at any given time. In our diagram above the number of pending operations determines the size of the orange resource bubble.
By tracking the number of pending send operations you can decide to do something different once the number gets “too high”. The Server Framework provides a TCP connection filter (see here) which will automatically queue subsequent sends in a per connection queue inside the framework. This allows you to control the amount of non-paged pool memory that is used by restricting the number of pending send operations but still allows you to queue data to be sent. In effect you’re adding another resource bubble and taking control of the size of both of the bubbles. You then use subsequent send completions to drive new asynchronous send requests which take their data from the data that you have queued for transmission and when the data queue is empty and the number of pending asynchronous send operations is below your limit the sends can send directly. This design allows you to maintain control of non-paged pool usage and allows you more flexibility over what you do when you are queueing too much data in the sending application.
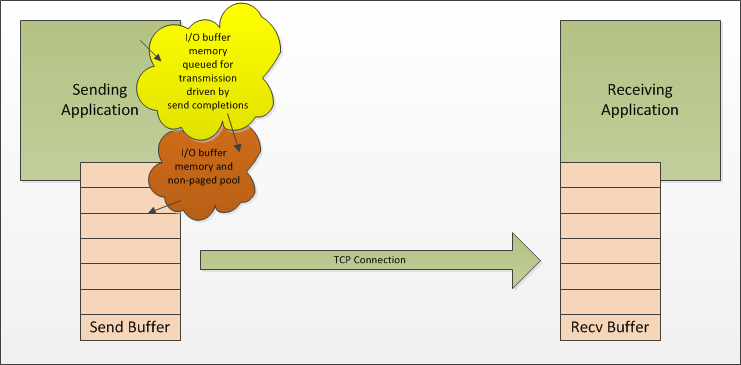
Queue the send operations
There’s still a problem if the receiving application can not catch up with the amount of data that is being generated on the sender, but now you have a way to throttle the sender as you know how many send operations are outstanding and, if you’re buffering outside of the Windows Overlapped I/O system as we do in The Server Framework, you can make decisions when a connection gets to a point where it has “too much” data buffered. The standard filter that The Server Framework provides allows you to easily decide to throttle the sender, drop pending data (if your application level protocol supports unreliable or optional messages) or simply abort the connection.
A similar scheme for managed code would be restricting the number of buffers that are pinned at one time and therefore limiting the damage to the garbage collector that the design of this part of the managed asynchronous networking API can cause. It’s still wise to allocate all of your I/O buffers as a single contiguous block of memory and suballocate from within that to force the pinned object into the large object heap and to minimise the problems caused by pinned I/O buffers.
Conclusion
The main thing to realise here is that if you use ANY of the asynchronous network send APIs on Windows, managed or unmanaged, then you are handing control over the lifetime of your send buffers to the receiving application and the network. Failure to actively manage the number outstanding asynchronous send operations that you have pending at any one time means that your application could run out of memory simply because a client connects to you over a slow network. Worse than this, it means that your application could, potentially, exhaust the non-paged pool memory of the machine on which it’s running and this could cause drivers to fail and the operating system to become unstable.