Reducing context switches and increasing performance
I’ve been working on a “big” new release for some time, too long actually. It has steadily been accumulating new features for over a year but the arrival of my second son in July last year and masses of client work has meant that it has repeatedly been pushed on the back burner. Well, no more, Release 6.6 is now in the final stages of development and testing (so I won’t be adding more new features) and hopefully will see a release in Q2
I’m planning a “what’s new in 6.6” blog posting which will detail all of the major changes but first I’d like to show you the results of some performance tuning that I’ve been doing. Most people are familiar with the quote from Donald Knuth, “premature optimization is the root of all evil”, and it’s often used as a stick to beat people with when they want to tweak low level code to “make things faster”. Yet the full quote is more interesting; “We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.”. I like to think that much of what I’ve done in 6.6 is in that 3% but even if it isn’t it’s still optimisation that comes for free to users of the framework. What’s more, the first change also removes complexity and makes it much easier to write correct code using the framework.
Since explaining the changes is pretty heavy going lets jump to the pictures of the results first.
This is the “before” graph; a v6.5.9 Open SSL Server.
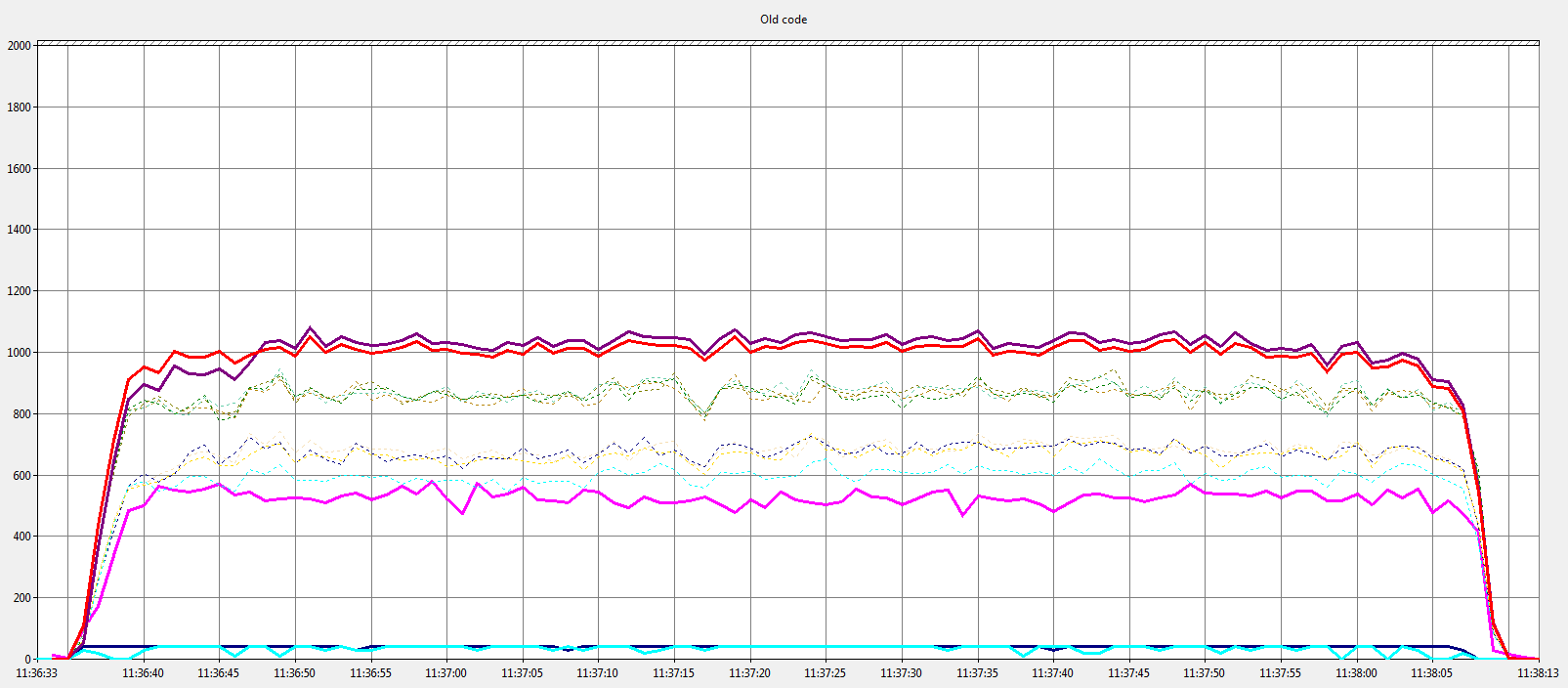
Performance of a 6.5.9 Open SSL Server
And this is the “after” graph; a v6.6 server.
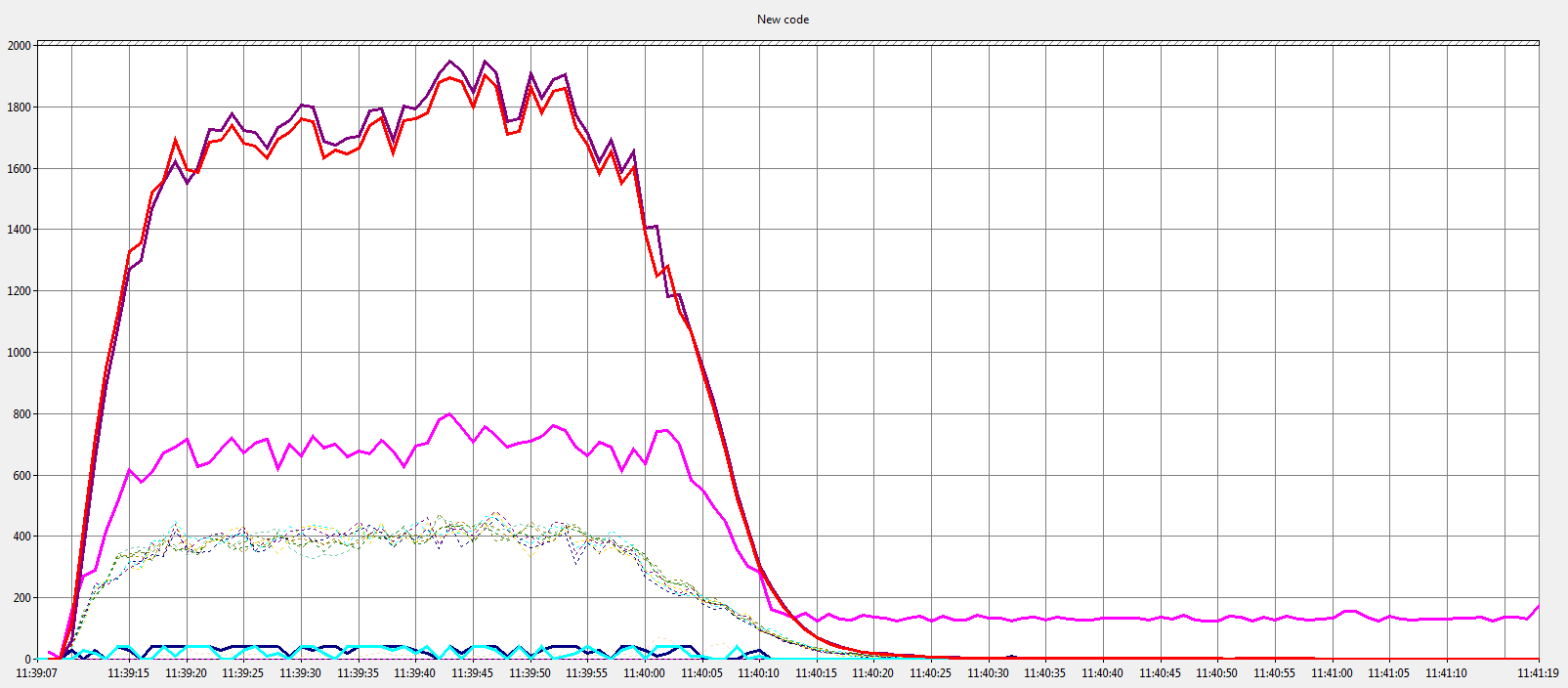
Performance of a 6.6 Open SSL Server
The important things are the red and purple lines (bytes processed/sec) where higher values are better. The next important are the faint dotted lines (thread context switches) where lower values are better.
What the graphs above show is that with the new changes in 6.6 a server can process more data in less time with fewer thread context switches.
These tests were run on a dual quad-core Xeon E5320 and pushed the box to around 80% cpu usage; the 6.6 test using slightly more cpu but for much less time. The results have been far less dramatic, but still positive, on our Core i7-3930K (12 core), but it’s hard to push it above 30% cpu utilisation.
Changes to the IOCP processing loop
Although I/O completion ports are a great way to distribute work amongst a pool of threads and to minimise context switching by using the threads in LIFO order it’s easy to squander performance with simple design mistakes. Sometimes these mistakes are so obvious that they get fixed immediately and sometimes the problems that they cause take longer to show and so the design is kept around and obtains a momentum of its own that makes it harder and harder to change. Most code, no doubt, has many of these mistakes and most of the time they’re not serious enough to bother changing. The Server Framework had a bit of broken design at its heart and over the years more and more new features have had to fight with this mistake and code has been changed to make things work with the original design rather than simply admitting the mistake and removing it. Well, now it’s gone. The mistake was in how we dealt with multiple completions for a single socket.
The main part of an IOCP based system is its processing loop. A pool of threads wait on the IOCP and when a completion packet is available a thread processes it and then loops back to wait on the IOCP again. In The Server Framework the thread likely works with a “socket” and a “buffer”, the buffer is per-operation data and the socket is per-connection data. A normal series of events might be for a read to complete and for the thread that is processing this read to issue one or more writes and then, possibly, issue another read. It’s quite normal for the writes to complete before the current thread has finished processing the current read completion and it’s often the case that the subsequent read request will also complete before the current thread has looped around to wait on the IOCP. All of this will likely cause more threads to be released from the IOCP to process the new completions. In simple systems this doesn’t matter too much, but if your write completions are driving your TCP flow control system and your reads cause your connection object to hold per-connection locks then having multiple threads trying to process the same connection simply leads to contention and unnecessary context switching as the subsequent completions block on the locks held by the completion that was originally being processed. In Windows Vista and later it’s possible to process completions “inline” by telling the I/O system that overlapped operations that complete immediately should return success rather than queue a completion packet to the IOCP, but this can then cause unexpected recursion unless your design was specifically created to queue these inline completions, a read request that results in an inline completion and which processes that completion recursively could easily result in another read request which completes inline and so the recursion becomes deeper. Ever since we added code to enable inline completions we’ve had code to help fight the recursion problem (rather than fixing the problem and simply queuing these completions for processing once the current completion is done with), this made reasoning about your own client code more complex due to the fact that in some situations a read request will result in a recursive call of your read completion handler and in others it wont.
The fix for these issues is pretty straight forward even though it’s a fairly fundamental change to our IOCP processing loop. It requires each connection to have a queue of completion buffers that it can process and for any completion that occurs on a connection whilst a thread is already processing completions for that connection to simply be added to the queue and processed in sequence rather than in parallel. Given that complex servers often have some shared state in the connection object it’s considerably more efficient in terms of threads to work this way and reduces the number of IOCP threads that need to be released to process completions. It also completely removes the any recursion issues. The best thing about this change is that it happens completely inside The Server Framework and so you get most of the benefits without needing to do anything at all to your client code.
Of course, once there’s no chance of the framework recursively calling into you there may be other optimisations and code changes that you can make. We’re still reviewing and adjusting some of the code in the framework to remove the additional complexity that was required when recursive calls were possible; things like the TCP stream filtering system, the filters for SSL, compression and flow control, etc. can all become slightly simpler.
Reduced STL usage
Another optimisation which has context switching implications is switching from using our “buffer lists” to using the new “buffer chains”. The buffer lists were all based on STL containers whereas the buffer chains are simple linked lists which use a pointer stored in the buffer itself to link to the next buffer. The simple removal of STL and the associated memory allocation and deallocation required when adding and removing elements has had quite a significant effect in thread contention and context switching. The new collections have a single lock which is only touched by threads that access that particular data structure whereas the STL based containers had this same lock plus whatever locking was required to access the process-wide heap for memory allocation. This reduces the number of threads that could contend for locks during container operations from all of the threads in the process to all of the threads concurrently working on a single connection. Thanks to the per-connection completion queue change this reduces the contention to zero in many cases.
Per-socket buffer pooling
Finally we’ve managed to address the main point of contention in server designs using The Server Framework, that of the buffer allocator’s lock. In many servers the hottest lock in the system is the lock used to protect the buffer allocator’s data structures. Many servers have a single buffer allocator and often every read or write requires buffers to be allocated from it and then released back to it. Once again the completion queue change has helped somewhat in that there are fewer threads processing completions and so less contention for the allocator’s lock, but there was still scope for improvement. In the past we’ve tried a variety of different allocator designs, from lock free, to allocators with private heaps, and per thread sub-pools. In general the problem has always been that the new allocators are either extremely complicated to configure or that even when configured correctly they fail to provide that much of an improvement over the base allocator. In this release we’ve tried something a little new and it seems to work well. Each socket now has it’s own pool of buffers for reuse; this is something we initially investigated in the stream compression filter in earlier releases. In 6.6. all code can now release buffers to a socket’s pool rather than the general allocator. The socket makes sure that excess buffers are released to the allocator if the pool gets too full, but otherwise the socket keeps buffers for reuse. Of course there’s now a corresponding way to allocate from the socket’s pool (and if that’s empty to seamlessly fall back on the allocator). These per socket pools are configured in the socket allocator’s constructor and, coupled with the completion queue change, they dramatically reduce the contention on the underlying buffer allocator.
The socket pooling changes have been so successful that we’re planning to deprecate all of the complicated buffer allocators shortly and encourage everyone to switch to using the new smart pointers and allocation techniques which take advantage of the per-socket pooling.
Wrapping up
The good news is that all of these changes occur inside the framework and the changes required to your code is minimal. You just get the performance gains for free.